

使用curl通过链接的方式去获取这个页面的所有内容

温馨提示:这篇文章已超过1173天没有更新,请注意相关的内容是否还可用!
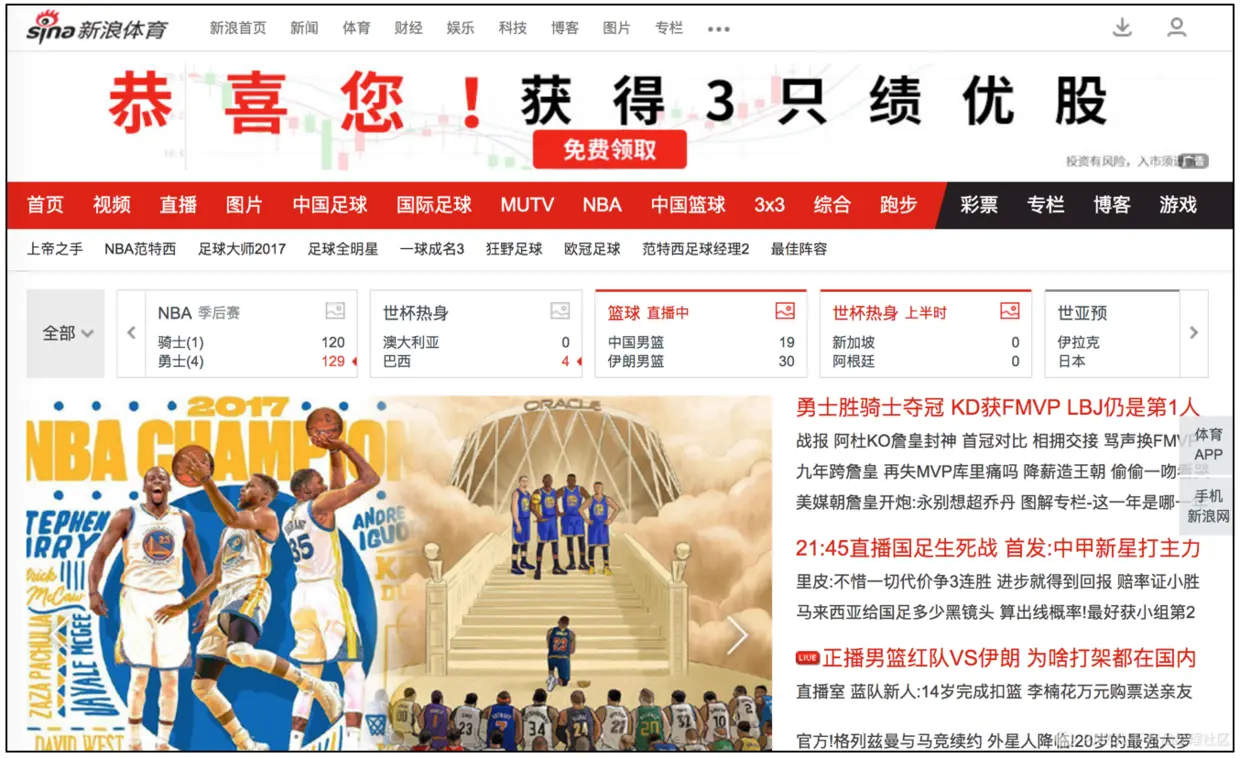
在一次做网站的之后,需要抓取一些其它网站的新闻,在此处介绍一种使用curl通过链接的方法去获得这个页面的所有内容,然后再借助正则匹配获得必须的内容。不是所有网站都能抓取需要有页面规律从而去抓取如下图

这些有规律的新闻列表php文章采集系统源码,不过新闻的详情内容必须重新单独的去抓取,
代码:
$url=;//要抓取的链接新闻列表
$url=('&','&',$url);
("-type:text/html;=utf-8");
$ch=();
($ch,,$url);
($ch,ER,0);//除去https里面的s
($ch,ER,1);//关闭直接输出
$=($ch);
($ch);//关闭会话
此处要确定能否抓取到了页面的内容可以打印下来看一下
如果没有抓取到要留意一下页面的编码格式使用iconv()转化一下内容编码
//$=iconv('gbk','utf-8',$);
$='#(.*?)(.*?)(.*?)(.*?)(.*?)
(.*?)
(.*?)
#is';
($,$,$);//进行正规匹配获得自己要的内容
//循环取出需要的内容数组
($as$k=>$var){
if($k==2||$k==3||$k==5||$k==7){
$b=(($[$k]));
$array[]=$b;
}
}
得到数据变量后就可以按照需求去添加数据了
内容详情需要抓取就获得到新闻内容页的链接同样使用curl去获得信息
要切记的就是正则表达式里面的html需要跟页面的格式一样,你可以去原网页点右键查看源代码,查看格式,把要读取的html复制出来,如果还是有不能抓取的内容或许就是格式不恰当有也许有的地方是少空格以及多空格,这个之后直接在标签之间(.*?)。也可以一点一点的匹配看详细是什么部分没有匹配到。
天隆网络为用户提供网站开发定制服务,网站制作居于LINUX+PHP+MYSQL框架php文章采集系统源码,欢迎用户咨询我们建站热线
本文来自网络,如有侵权请联系网站客服进行删除
 您阅读本篇文章共花了:
您阅读本篇文章共花了: 


界面清爽、整洁,运行环境需支持")




还没有评论,来说两句吧...